Three-Star
Team Members
Progress
Assignment 1
Image Profiling
Chosen to profile image profiling as shown here: http://www.dreamincode.net/forums/topic/76816-image-processing-tutorial/ , using the sample program files (main/image.h/image.cpp)
pulled PGM sample files from here: https://userpages.umbc.edu/~rostamia/2003-09-math625/images.html
file sizes being 512x512, about 262 KB each file
Compiled to produce a flat profile and a call graph
>g++ -g -O2 -pg -o main main.cpp
>main a.pgm result.pgm
Note: Enlarged image by max permitted by program (5) to get more viewable results, since the profile without enlarging it produces non-significant results

The results of the flat profile:

The results of the call graph


Rotate image function is one of the longer running functions and looks like it has potential for parallelization.

LZW Data Compression Algorithm
Timothy Moy profiled.
Original algorithm: https://codereview.stackexchange.com/questions/86543/simple-lzw-compression-algorithm
Raw Flat profile (50Mb Test file for compression):
Each sample counts as 0.01 seconds.
% cumulative self self total time seconds seconds calls us/call us/call name 35.52 4.23 4.23 compress(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) 27.54 7.51 3.28 102062309 0.03 0.03 std::_Hashtable<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, int>, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, int> >, std::__detail::_Select1st, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<true, false, true> >::_M_find_before_node(unsigned int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, unsigned int) const 20.15 9.91 2.40 204116423 0.01 0.01 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_replace_aux(unsigned int, unsigned int, unsigned int, char) 8.23 10.89 0.98 49629412 0.02 0.05 std::__detail::_Map_base<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, int>, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, int> >, std::__detail::_Select1st, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<true, false, true>, true>::operator[](std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) 4.28 11.40 0.51 52428800 0.01 0.01 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_assign(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) 3.02 11.76 0.36 52436762 0.01 0.01 show_usage() 1.26 11.91 0.15 _Z22convert_char_to_stringB5cxx11PKci 0.00 11.91 0.00 4097 0.00 0.00 std::_Hashtable<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, int>, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, int> >, std::__detail::_Select1st, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::__detail::_Mod_range_hashing, std::__detail::_Default_ranged_hash, std::__detail::_Prime_rehash_policy, std::__detail::_Hashtable_traits<true, false, true> >::_M_insert_unique_node(unsigned int, unsigned int, std::__detail::_Hash_node<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, int>, true>*) 0.00 11.91 0.00 22 0.00 0.01 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_mutate(unsigned int, unsigned int, char const*, unsigned int) 0.00 11.91 0.00 1 0.00 0.00 _GLOBAL__sub_I__Z18convert_int_to_binB5cxx11i 0.00 11.91 0.00 1 0.00 28.13 std::_Hashtable<std::__cxx11::basic_
Summarized Flat Profile (50Mb Test file for compression):
% cumulative self self total time seconds seconds calls us/call us/call name 35.52 4.23 4.23 compress() 27.54 7.51 3.28 102062309 0.03 0.03 std::_Hashtable 20.15 9.91 2.40 204116423 0.01 0.01 std::__cxx11::basic_string 8.23 10.89 0.98 49629412 0.02 0.05 std::__detail::_Map_base 4.28 11.40 0.51 52428800 0.01 0.01 std::__cxx11::basic_string 3.02 11.76 0.36 52436762 0.01 0.01 show_usage() 1.26 11.91 0.15 _Z22convert_char_to_stringB5cxx11PKci 0.00 11.91 0.00 4097 0.00 0.00 std::_Hashtable 0.00 11.91 0.00 22 0.00 0.01 std::__cxx11::basic_string 0.00 11.91 0.00 1 0.00 0.00 _GLOBAL__sub_I__Z18convert_int_to_binB5cxx11i 0.00 11.91 0.00 1 0.00 28.13 std::_Hashtable<std::__cxx11::basic_
Note how the compress() function takes up the largest amount of time (over one third), then the other functions which take up over 10% of the time are library functions. It is highly unlikely we could parallelize the library functions. The other functions that take up under 10% of the time will probably not give enough improvement in time to make a significant impact.
Thus, the function we should focus on is the compress function.
Summary of Compress() Profiles
| Size (MB) | Compress() time in seconds |
|---|---|
| 10 | 0.96 |
| 15 | 1.35 |
| 20 | 1.8 |
| 25 | 2.14 |
| 30 | 2.64 |
| 35 | 3.16 |
| 40 | 3.45 |
| 45 | 4.24 |
| 50 | 4.23 |
The compress function source code:
void compress(string input, int size, string filename) {
unordered_map<string, int> compress_dictionary(MAX_DEF);
//Dictionary initializing with ASCII
for ( int unsigned i = 0 ; i < 256 ; i++ ){
compress_dictionary[string(1,i)] = i;
}
string current_string;
unsigned int code;
unsigned int next_code = 256;
//Output file for compressed data
ofstream outputFile;
outputFile.open(filename + ".lzw");
// Possible area for improvement via reduction
for(char& c: input){
current_string = current_string + c;
if ( compress_dictionary.find(current_string) ==compress_dictionary.end() ){
if (next_code <= MAX_DEF)
compress_dictionary.insert(make_pair(current_string, next_code++));
current_string.erase(current_string.size()-1);
outputFile << convert_int_to_bin(compress_dictionary[current_string]);
current_string = c;
}
}
if (current_string.size())
outputFile << convert_int_to_bin(compress_dictionary[current_string]);
outputFile.close();
}
There are two loops which show possibility of parallelization:
for ( int unsigned i = 0 ; i < 256 ; i++ ){
compress_dictionary[string(1,i)] = i;
}
and
for(char& c: input){
current_string = current_string + c; // Possible area for improvement via reduction
if ( compress_dictionary.find(current_string) ==compress_dictionary.end() ){
if (next_code <= MAX_DEF)
compress_dictionary.insert(make_pair(current_string, next_code++));
current_string.erase(current_string.size()-1);
outputFile << convert_int_to_bin(compress_dictionary[current_string]);
current_string = c;
}
}
The first for loop is constant and probably won't show much improvement if we parallelize it.
Note the comment above the second for loop notes we can do something like this:
for (int i = 1; i < n; i+=) a[0] += a[i];
changed to
for (int s = 1; s <= n/2; s*=2)
for(int j = 0; j < n; j +=2 * s)
a[j] += a[j + s];
As such, the major hotspot in this function is the second for loop. This is especially true since the file might be very large and we may be dealing with millions of characters! The one thing we need to worry about is that order does seem to matter for the second for loop.
Conclusion
We decided to go with image profiling. It is a pretty simple parallelization since the transformation functions are matrix transformations which don't care about which element is processed first.
There are some possible issues with working with the simple-lzw-compression-algorithm and CUDA. You cannot use the C++ string type in a kernel because CUDA does not include a device version of the C++ String library that would be able run on the GPU. Even if it was possible to use string in a kernel, it's not something you would want to do because string handles memory dynamically, which would be likely to be slow.
Essentially, using chars on the gpu would require we use 8-bit arithmetic and need to convert from 32-bit arithmetic for operations. On top of that, the compress function refers to a map of strings/int pairs to shrink the size of the file. Even if we did manage the character operations, it would need to somehow use the string map to get the corresponding integer which could lead to being unable to use device memory for optimization.
Assignment 2
Original CPU Implementation:
void Image::rotateImage(int theta, Image& oldImage)
/*based on users input and rotates it around the center of the image.*/
{
int r0, c0;
int r1, c1;
int rows, cols;
rows = oldImage.N;
cols = oldImage.M;
Image tempImage(rows, cols, oldImage.Q);
float rads = (theta * 3.14159265)/180.0;
r0 = rows / 2;
c0 = cols / 2;
for(int r = 0; r < rows; r++)
{
for(int c = 0; c < cols; c++)
{
r1 = (int) (r0 + ((r - r0) * cos(rads)) - ((c - c0) * sin(rads)));
c1 = (int) (c0 + ((r - r0) * sin(rads)) + ((c - c0) * cos(rads)));
if(inBounds(r1,c1))
{
tempImage.pixelVal[r1][c1] = oldImage.pixelVal[r][c];
}
}
}
for(int i = 0; i < rows; i++)
{
for(int j = 0; j < cols; j++)
{
if(tempImage.pixelVal[i][j] == 0)
tempImage.pixelVal[i][j] = tempImage.pixelVal[i][j+1];
}
}
oldImage = tempImage;
}
Parallelized Code (done by Timothy Moy, Derrick acted as consulting for how to use the program):
Kernels
__device__ bool inBounds(int row, int col, int maxRow, int maxCol) {
if (row >= maxRow || row < 0 || col >= maxCol || col < 0)
return false;
//else
return true;
}
__global__ void rotateKernel(int* oldImage, int* newImage, int rows, int cols, float rads) {
int r = blockIdx.x * blockDim.x + threadIdx.x;
int c = blockIdx.y * blockDim.y + threadIdx.y;
int r0 = rows / 2;
int c0 = cols / 2;
float sinRads = sinf(rads);
float cosRads = cosf(rads);
/*__shared__ int s[ntpb * ntpb];
s[r * cols + c] = oldImage[r * cols + c];*/
if (r < rows && c < cols)
{
int r1 = (int)(r0 + ((r - r0) * cosRads) - ((c - c0) * sinRads));
int c1 = (int)(c0 + ((r - r0) * sinRads) + ((c - c0) * cosRads));
if (inBounds(r1, c1, rows, cols))
{
newImage[r1 * cols + c1] = oldImage[r * cols + c];
}
}
}
Modified Function
void Image::rotateImage(int theta, Image& oldImage)
/*based on users input and rotates it around the center of the image.*/
{
int r0, c0;
int r1, c1;
int rows, cols;
rows = oldImage.N;
cols = oldImage.M;
Image tempImage(rows, cols, oldImage.Q);
float rads = (theta * 3.14159265)/180.0;
// workspace start
// - calculate number of blocks for n rows assume square image
int nb = (rows + ntpb - 1) / ntpb;
// allocate memory for matrices d_a, d_b on the device
// - add your allocation code here
int* d_a;
check("device a", cudaMalloc((void**)&d_a, rows* cols * sizeof(int)));
int* d_b;
check("device b", cudaMalloc((void**)&d_b, rows* cols * sizeof(int)));
// copy h_a and h_b to d_a and d_b (host to device)
// - add your copy code here
check("copy to d_a", cudaMemcpy(d_a, oldImage.pixelVal, rows * cols * sizeof(int), cudaMemcpyHostToDevice));
//check("copy to d_b", cudaMemcpy(d_b, tempImage.pixelVal, rows * cols * sizeof(int), cudaMemcpyHostToDevice));
// launch execution configuration
// - define your 2D grid of blocks
dim3 dGrid(nb, nb);
// - define your 2D block of threads
dim3 dBlock(ntpb, ntpb);
// - launch your execution configuration
rotateKernel<<<dGrid, dBlock >>>(d_a, d_b, rows, cols, rads);
check("launch error: ", cudaPeekAtLastError());
// - check for launch termination
// synchronize the device and the host
check("Synchronize ", cudaDeviceSynchronize());
// copy d_b to tempImage (device to host)
// - add your copy code here
check("device copy to hc", cudaMemcpy(tempImage.pixelVal, d_b, rows * cols * sizeof(int), cudaMemcpyDeviceToHost));
// deallocate device memory
// - add your deallocation code here
cudaFree(d_a);
cudaFree(d_b);
// reset the device
cudaDeviceReset();
// workspace end
for(int i = 0; i < rows; i++)
{
for(int j = 0; j < cols; j++)
{
if(tempImage.pixelVal[i * M + j] == 0)
tempImage.pixelVal[i * M + j] = tempImage.pixelVal[i * M + j+1];
}
}
oldImage = tempImage;
}
Profiling (Done by Derrick Leung)
| Function | CPU-Only | GPU-CPU | speedup(%) |
| Cuda Memory Allocation | s | 1164 ms | % |
| Copy Image to Device memory | s | 6 ms | % |
| Kernel | s | 0 ms | % |
| Copy device image to host temp variable | s | 6 ms | % |
| copy temp image to original image variable | s | 43 ms | % |
| Total Rotation Time (no allocation, with memcpy) | 1717ms | 55ms | % |
| Total Run Time | 1775 ms | 1294 ms | % |
Comparisons
| Rotation Run Time (exclude memory allocation) | Total Run Time | |||||
|---|---|---|---|---|---|---|
| Size of Picture | CPU-Only | GPU-CPU | speedup ratio | CPU-Only | GPU-CPU | speedup ratio |
| 512x512 | 67 ms | 2ms | 33.50 | 71 ms | 372 ms | .19 |
| 2x enlarged | 265 ms | 7 ms | 37.85 | 277 ms | 410 ms | .67 |
| 3x enlarged | 608 ms | 23 ms | 26.43 | 630 ms | 427 ms | 1.47 |
| 4x enlarged | 1091 ms | 37 ms | 29.48 | 1129 ms | 446 ms | 2.53 |
| 5x enlarged | 1717 ms | 55 ms | 31.22 | 1775 ms | 476 ms | 3.73 |


Excel Sheet File:Assignment2 profile.xlsx.txt
Source Code: File:Image.cu.txt File:Image.h.txt File:Main.cpp.txt
Assignment 3
Coalesced Memory (Derrick Leung)
Using Coalesced Memory (changed matrix access from column to row)(16x16 block size) (Derrick Leung)
| Uncoalesced | Coalesced | |||||
|---|---|---|---|---|---|---|
| Size of Picture | memcpy | rotate kernel | total runtime | memcpy | rotate kernel | total runtime |
| 512x512 | 0.50ms | 0.89ms | 91.77ms | 0.51ms | 0.89ms | 97.13ms |
| 2x enlarged | 1.91ms | 3.56ms | 97.78ms | 1.81ms | 3.54ms | 98.82ms |
| 3x enlarged | 4.63ms | 7.97ms | 107.07ms | 4.38ms | 7.95ms | 105.41ms |
| 4x enlarged | 7.71ms | 14.15ms | 112.54ms | 7.61ms | 14.10ms | 111.86ms |
| 5x enlarged | 12.80ms | 22.10ms | 131.18ms | 12.60ms | 22.00ms | 126.04ms |

Changing the way memory is accessed doesn't seem to have any significant improvements/changes to time
Tiling (Timothy Moy)
Tiling ended up being a no go as we didn't even have a use of implementing the shared memory. Since we weren't using shared memory, and tiling improves performance via shared memory we opted not to try implementing it and try other methods instead.
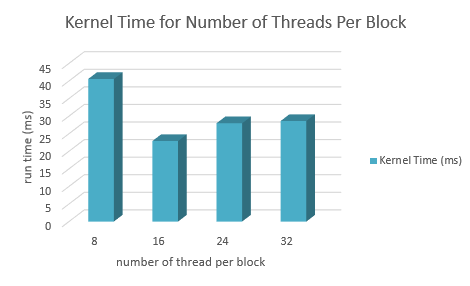
Block Size (Timothy Moy)
The first quick method to try and improve it was to change the block size. Playing with the block size changed the kernel run times, but it wasn't apparent what exactly causes it.
{kind=link}
In the end, a block size of 16 by 16 proved to be best for run times.
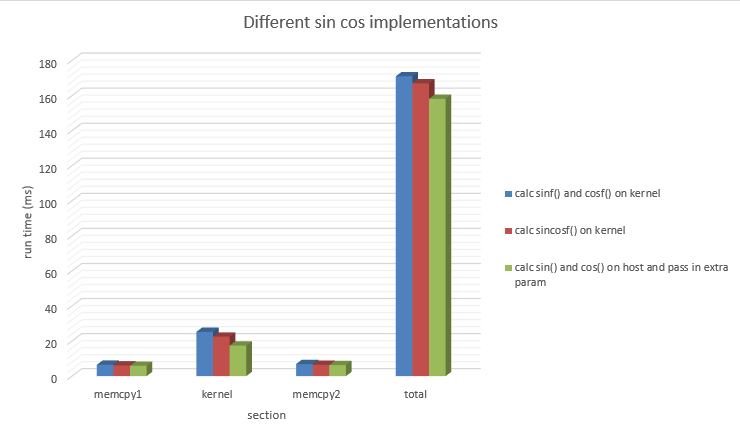
Moving Repeated Calculations to the Host (Timothy Moy)
I then tried merging the sinf() and cosf() function calls into one via sincosf() so that the kernel made less function calls. That proved to be trim the run times a bit, but then I noticed that sin and cos never change since our angle never changes. Thus, this led to testing of the sin and cos functions to use the Host to calculate it and pass them in as parameters for the kernel. The result was a much more significant run time since our kernel is no longer calculating the same number in each thread.
{kind=link}
There may be other variables that could be moved outside the kernel like r0 and c0, but due to time limitations they weren't tested.