|
|
| (16 intermediate revisions by 2 users not shown) |
| Line 19: |
Line 19: |
| | == Intel Math Library == | | == Intel Math Library == |
| | | | |
| − | # Features
| + | === Introduction === |
| | + | The Intel oneAPI Math Kernel Library (MKL) is the fastest and most widely used math library for all intel based systems. It helps you reach high performance with its enhanced library of optimized math routines. It allows for faster math processing times, increased performance and shorter development times. The MKL supports seven main features; Linear Algebra, Sparse Linear Algebra, Data Fitting, Fast Fourier Transformations, Random Number Generation, Summary Statistics and Vector Math. These features will allow you to optimize applications for all current and future intel CPUs and GPUs. |
| | + | === Features === |
| | | | |
| − | ## Linear Algebra
| + | ==== Linear Algebra ==== |
| | Intel has implemented linear algebra functions that follow industry standards ([BLAS](http://www.netlib.org/blas/) and [LAPACK](http://www.netlib.org/lapack/)). These functions include those that can do the following: | | Intel has implemented linear algebra functions that follow industry standards ([BLAS](http://www.netlib.org/blas/) and [LAPACK](http://www.netlib.org/lapack/)). These functions include those that can do the following: |
| − | - Level 1: Vector-vector operations
| |
| − | - Level 2: Matrix-vector operations
| |
| − | - Level 3: Matrix-matrix operations
| |
| | | | |
| − | ## Sparse Linear Algebra Functions
| + | Level 1: Vector-vector operations |
| − | Able to perform low-level inspector-executor routines on sparse matrices, such as:
| |
| − | - Multiply sparse matrix with dense vector | |
| − | - Multiply sparse matrix with dense matrix
| |
| − | - Solve linear systems with triangular sparse matrices
| |
| − | - Solve linear systems with general sparse matrices
| |
| − | A sparse matrix is matrix that is mostly empty, these are common in machine learning applications. Using standard linear algebra functions would lead to poor performance and would require greater amounts of storage. Specially writen sparse linear algebra functions have better performance and can better compress matrices to save space.
| |
| | | | |
| | + | Level 2: Matrix-vector operations |
| | | | |
| − | ## Fast Fourier Transforms
| + | Level 3: Matrix-matrix operations |
| − | Enabling technology today such as most digital communications, audio compression, image compression, satellite tv, FFT is at the heart of it.
| |
| − | A fast Fourier transform (FFT) is an algorithm that computes the discrete Fourier transform (DFT) of a sequence, or its inverse (IDFT).
| |
| | | | |
| − | ## Random Number Generator
| + | There are many different implementations of these subprograms available. These different implementations are created with different purposes or platforms in mind. Intel's oneAPI implementation heavily focuses on performance, specifically with x86 and x64 in mind. |
| − | The Intel Math Kernal Library has an interface for RNG routines that use pseudorandom, quasi-random,
| |
| − | and non-deterministic generators. These routines are developed the calls to the highly optimized Basic Random Number Generators (BRNGs).
| |
| − | All BRNGs differentiate in speeds and properties so its easy to find a optimized one for your application.
| |
| | | | |
| − | All RNG routines can be categorized in several different categories.
| + | [[File:BLAS.png]] |
| − | - Engines - hold the state of a generator
| |
| − | - Transformation classes - holds different types of statistical distribution
| |
| − | - Generate function - the routine that obtains the random number from the statistical distribution
| |
| − | - Services - using routines that can modify the state of the engine
| |
| | | | |
| − | The generation of numbers is done in 2 steps:
| + | ==== Sparse Linear Algebra Functions ==== |
| − | 1. generate the state using the engine.
| + | Able to perform low-level inspector-executor routines on sparse matrices, such as: |
| − | 2. iterate over the values and the output is the random numbers.
| |
| | | | |
| − | ## Data Fitting
| + | * Multiply sparse matrix with dense vector |
| − | The Intel Math Kernal Library provide spline-based interpolation that can be ultilized to approximate functions for derivatives, integrals and cell search operations.
| |
| | | | |
| − | Data Fitting routines use the following workflow to process a task:
| + | * Multiply sparse matrix with dense matrix |
| − | - Create a task or multiple tasks.
| |
| − | - Modify the task parameters.
| |
| − | - Perform a Data Fitting computation.
| |
| − | - Destroy the task or tasks.
| |
| | | | |
| − | Data Fitting functions:
| + | * Solve linear systems with triangular sparse matrices |
| − | - Task Creation and Initialization Routines.
| |
| − | - Task Configuration Routines.
| |
| − | - Computational Routines.
| |
| − | - Task Destructors.
| |
| | | | |
| − | ## Summary Statistics
| + | * Solve linear systems with general sparse matrices |
| − | The Intel Math Kernal Library has an interface for Summary Statistics that can compute estimates for
| |
| − | single, double and multi-dimensional datasets. For example, such parameters may be precision, dimensions of user data, the matrix of the observations, or shapes of data arrays.
| |
| − | First you create and intialize the object for the dataset, then you call the summary statistics routine to calculate the estimate.
| |
| | | | |
| − | Summary Statistics calculate:
| + | A sparse matrix is matrix that is mostly empty, these are common in machine learning applications. Using standard linear algebra functions would lead to poor performance and would require greater amounts of storage. Specially written sparse linear algebra functions have better performance and can better compress matrices to save space. |
| − | - Raw and central sums/moments up to the fourth order.
| |
| − | - Variation coefficient.
| |
| − | - Skewness and excess kurtosis.
| |
| − | - Minimum and maximum.
| |
| | | | |
| − | Additional Features:
| + | [[File:Sparse.png]] |
| − | - Detect outliers in datasets.
| |
| − | - Support missing values in datasets.
| |
| − | - Parameterize correlation matrices.
| |
| − | - Compute quantiles for streaming data.
| |
| | | | |
| − | ## Vector Math
| + | ==== Fast Fourier Transforms ==== |
| | + | Enabling technology today such as most digital communications, audio compression, image compression, satellite tv, FFT is at the heart of it. |
| | + | A fast Fourier transform (FFT) is an algorithm that computes the discrete Fourier transform (DFT) of a sequence, or its inverse (IDFT). |
| | | | |
| − | There are two main set of functions for the Vector Math library that the intel MKL uses they are
| + | [[File:Download.jpg]] |
| − | - VM Mathematical Functions�Which allows for it to compute values of mathematical functions e.g. sine, cosine, exponential, or logarithm on vectors that are stored in contiguous memory.
| |
| − | - VM Service Functions are used for showing when catching errors made in the calculations or accuracy. Such as catching error codes or error messages from improper calculations.
| |
| | | | |
| | + | ==== Random Number Generator ==== |
| | + | The Intel Math Kernel Library has an interface for RNG routines that use pseudorandom, quasi-random, |
| | + | and non-deterministic generators. These routines are developed the calls to the highly optimized Basic Random Number Generators (BRNGs). |
| | + | All BRNGs differentiate in speeds and properties so its easy to find a optimized one for your application. |
| | | | |
| − | # Code Samples
| + | All RNG routines can be categorized in several different categories. |
| − | These samples are directly from the Intel Math Kernal Library code examples.
| |
| | | | |
| − | ## Vector Add
| + | * Engines - hold the state of a generator |
| − | ```//==============================================================
| |
| − | // Vector Add is the equivalent of a Hello, World! sample for data parallel
| |
| − | // programs. Building and running the sample verifies that your development
| |
| − | // environment is setup correctly and demonstrates the use of the core features
| |
| − | // of DPC++. This sample runs on both CPU and GPU (or FPGA). When run, it
| |
| − | // computes on both the CPU and offload device, then compares results. If the
| |
| − | // code executes on both CPU and offload device, the device name and a success
| |
| − | // message are displayed. And, your development environment is setup correctly!
| |
| − | //
| |
| − | // For comprehensive instructions regarding DPC++ Programming, go to
| |
| − | // https://software.intel.com/en-us/oneapi-programming-guide and search based on
| |
| − | // relevant terms noted in the comments.
| |
| − | //
| |
| − | // DPC++ material used in the code sample:
| |
| − | // • A one dimensional array of data shared between CPU and offload device.
| |
| − | // • A device queue and kernel.
| |
| − | //==============================================================
| |
| − | // Copyright © Intel Corporation
| |
| − | //
| |
| − | // SPDX-License-Identifier: MIT
| |
| − | // =============================================================
| |
| − | #include <CL/sycl.hpp>
| |
| − | #include <array>
| |
| − | #include <iostream>
| |
| − | #if FPGA || FPGA_EMULATOR
| |
| − | #include <CL/sycl/INTEL/fpga_extensions.hpp>
| |
| − | #endif
| |
| | | | |
| − | using namespace sycl;
| + | * Transformation classes - holds different types of statistical distribution |
| | | | |
| − | // Array size for this example.
| + | * Generate function - the routine that obtains the random number from the statistical distribution |
| − | constexpr size_t array_size = 10000;
| |
| | | | |
| − | // Create an exception handler for asynchronous SYCL exceptions
| + | * Services - using routines that can modify the state of the engine |
| − | static auto exception_handler = [](sycl::exception_list e_list) {
| |
| − | for (std::exception_ptr const &e : e_list) {
| |
| − | try {
| |
| − | std::rethrow_exception(e);
| |
| − | }
| |
| − | catch (std::exception const &e) {
| |
| − | #if _DEBUG
| |
| − | std::cout << "Failure" << std::endl;
| |
| − | #endif
| |
| − | std::terminate();
| |
| − | }
| |
| − | }
| |
| − | };
| |
| | | | |
| − | //************************************
| + | The generation of numbers is done in 2 steps: |
| − | // Vector add in DPC++ on device: returns sum in 4th parameter "sum".
| |
| − | //************************************
| |
| − | void VectorAdd(queue &q, const int *a, const int *b, int *sum, size_t size) {
| |
| − | // Create the range object for the arrays.
| |
| − | range<1> num_items{size};
| |
| | | | |
| − | // Use parallel_for to run vector addition in parallel on device. This
| + | 1. generate the state using the engine. |
| − | // executes the kernel.
| |
| − | // 1st parameter is the number of work items.
| |
| − | // 2nd parameter is the kernel, a lambda that specifies what to do per
| |
| − | // work item. the parameter of the lambda is the work item id.
| |
| − | // DPC++ supports unnamed lambda kernel by default.
| |
| − | auto e = q.parallel_for(num_items, [=](auto i) { sum[i] = a[i] + b[i]; });
| |
| | | | |
| − | // q.parallel_for() is an asynchronous call. DPC++ runtime enqueues and runs
| + | 2. iterate over the values and the output is the random numbers. |
| − | // the kernel asynchronously. Wait for the asynchronous call to complete.
| |
| − | e.wait();
| |
| − | }
| |
| | | | |
| − | //************************************
| + | ==== Data Fitting ==== |
| − | // Initialize the array from 0 to array_size - 1
| + | The Intel Math Kernal Library provide spline-based interpolation that can be ultilized to approximate functions for derivatives, integrals and cell search operations. |
| − | //************************************
| |
| − | void InitializeArray(int *a, size_t size) {
| |
| − | for (size_t i = 0; i < size; i++) a[i] = i;
| |
| − | }
| |
| | | | |
| − | //************************************
| + | Data Fitting routines use the following workflow to process a task: |
| − | // Demonstrate vector add both in sequential on CPU and in parallel on device.
| |
| − | //************************************
| |
| − | int main() {
| |
| − | // Create device selector for the device of your interest.
| |
| − | #if FPGA_EMULATOR
| |
| − | // DPC++ extension: FPGA emulator selector on systems without FPGA card.
| |
| − | INTEL::fpga_emulator_selector d_selector;
| |
| − | #elif FPGA
| |
| − | // DPC++ extension: FPGA selector on systems with FPGA card.
| |
| − | INTEL::fpga_selector d_selector;
| |
| − | #else
| |
| − | // The default device selector will select the most performant device.
| |
| − | default_selector d_selector;
| |
| − | #endif
| |
| | | | |
| − | try {
| + | * Create a task or multiple tasks |
| − | queue q(d_selector, exception_handler);
| |
| | | | |
| − | // Print out the device information used for the kernel code.
| + | * Modify the task parameters |
| − | std::cout << "Running on device: "
| |
| − | << q.get_device().get_info<info::device::name>() << "\n";
| |
| − | std::cout << "Vector size: " << array_size << "\n";
| |
| | | | |
| − | // Create arrays with "array_size" to store input and output data. Allocate
| + | * Perform a Data Fitting computation |
| − | // unified shared memory so that both CPU and device can access them.
| |
| − | int *a = malloc_shared<int>(array_size, q);
| |
| − | int *b = malloc_shared<int>(array_size, q);
| |
| − | int *sum_sequential = malloc_shared<int>(array_size, q);
| |
| − | int *sum_parallel = malloc_shared<int>(array_size, q);
| |
| | | | |
| − | if ((a == nullptr) || (b == nullptr) || (sum_sequential == nullptr) ||
| + | * Destroy the task or tasks |
| − | (sum_parallel == nullptr)) {
| |
| − | if (a != nullptr) free(a, q);
| |
| − | if (b != nullptr) free(b, q);
| |
| − | if (sum_sequential != nullptr) free(sum_sequential, q);
| |
| − | if (sum_parallel != nullptr) free(sum_parallel, q);
| |
| | | | |
| − | std::cout << "Shared memory allocation failure.\n";
| + | Data Fitting functions: |
| − | return -1;
| |
| − | }
| |
| | | | |
| − | // Initialize input arrays with values from 0 to array_size - 1
| + | * Task Creation and Initialization Routines |
| − | InitializeArray(a, array_size);
| |
| − | InitializeArray(b, array_size);
| |
| | | | |
| − | // Compute the sum of two arrays in sequential for validation.
| + | * Task Configuration Routines |
| − | for (size_t i = 0; i < array_size; i++) sum_sequential[i] = a[i] + b[i];
| |
| | | | |
| − | // Vector addition in DPC++.
| + | * Computational Routines |
| − | VectorAdd(q, a, b, sum_parallel, array_size);
| |
| | | | |
| − | // Verify that the two arrays are equal.
| + | * Task Destructors |
| − | for (size_t i = 0; i < array_size; i++) {
| |
| − | if (sum_parallel[i] != sum_sequential[i]) {
| |
| − | std::cout << "Vector add failed on device.\n";
| |
| − | return -1;
| |
| − | }
| |
| − | }
| |
| | | | |
| − | int indices[]{0, 1, 2, (array_size - 1)};
| + | ==== Summary Statistics ==== |
| − | constexpr size_t indices_size = sizeof(indices) / sizeof(int);
| + | The Intel Math Kernal Library has an interface for Summary Statistics that can compute estimates for |
| | + | single, double and multi-dimensional datasets. For example, such parameters may be precision, dimensions of user data, the matrix of the observations, or shapes of data arrays. |
| | + | First you create and intialize the object for the dataset, then you call the summary statistics routine to calculate the estimate. |
| | | | |
| − | // Print out the result of vector add.
| + | Summary Statistics calculate: |
| − | for (int i = 0; i < indices_size; i++) {
| |
| − | int j = indices[i];
| |
| − | if (i == indices_size - 1) std::cout << "...\n";
| |
| − | std::cout << "[" << j << "]: " << j << " + " << j << " = "
| |
| − | << sum_sequential[j] << "\n";
| |
| − | }
| |
| | | | |
| − | free(a, q);
| + | * Raw and central sums/moments up to the fourth order. |
| − | free(b, q);
| |
| − | free(sum_sequential, q);
| |
| − | free(sum_parallel, q);
| |
| − | } catch (exception const &e) {
| |
| − | std::cout << "An exception is caught while adding two vectors.\n";
| |
| − | std::terminate();
| |
| − | }
| |
| | | | |
| − | std::cout << "Vector add successfully completed on device.\n";
| + | * Variation coefficient. |
| − | return 0;
| |
| − | }
| |
| − | ```
| |
| | | | |
| | + | * Skewness and excess kurtosis. |
| | | | |
| − | ## Math Mul
| + | * Minimum and maximum. |
| − | ```//==============================================================
| |
| − | // Copyright © 2020 Intel Corporation
| |
| − | //
| |
| − | // SPDX-License-Identifier: MIT
| |
| − | // =============================================================
| |
| | | | |
| − | /**
| |
| − | * Matrix_mul multiplies two large matrices both the CPU and the offload device,
| |
| − | * then compares results. If the code executes on both CPU and the offload
| |
| − | * device, the name of the offload device and a success message are displayed.
| |
| − | *
| |
| − | * For comprehensive instructions regarding DPC++ Programming, go to
| |
| − | * https://software.intel.com/en-us/oneapi-programming-guide and search based on
| |
| − | * relevant terms noted in the comments.
| |
| − | */
| |
| | | | |
| − | #include <CL/sycl.hpp>
| + | Additional Features: |
| − | #include <iostream>
| |
| − | #include <limits>
| |
| | | | |
| − | // dpc_common.hpp can be found in the dev-utilities include folder.
| + | * Detect outliers in datasets. |
| − | // e.g., $ONEAPI_ROOT/dev-utilities/<version>/include/dpc_common.hpp
| |
| − | #include "dpc_common.hpp"
| |
| | | | |
| − | using namespace std;
| + | * Support missing values in datasets. |
| − | using namespace sycl;
| |
| | | | |
| − | /**
| + | * Parameterize correlation matrices. |
| − | * Each element of the product matrix c[i][j] is computed from a unique row and
| |
| − | * column of the factor matrices, a[i][k] and b[k][j]
| |
| − | */
| |
| | | | |
| − | // Matrix size constants.
| + | * Compute quantiles for streaming data. |
| − | constexpr int m_size = 150 * 8; // Must be a multiple of 8.
| |
| − | constexpr int M = m_size / 8;
| |
| − | constexpr int N = m_size / 4;
| |
| − | constexpr int P = m_size / 2;
| |
| | | | |
| − | /**
| + | ==== Vector Math ==== |
| − | * Perform matrix multiplication on host to verify results from device.
| |
| − | */
| |
| − | int VerifyResult(float (*c_back)[P]);
| |
| | | | |
| − | int main() {
| + | There are two main set of functions for the Vector Math library that the intel MKL uses they are: |
| − | // Host memory buffer that device will write data back before destruction.
| |
| − | float(*c_back)[P] = new float[M][P];
| |
| | | | |
| − | // Intialize c_back
| + | * VM Mathematical Functions Which allows for it to compute values of mathematical functions e.g. sine, cosine, exponential, or logarithm on vectors that are stored in contiguous memory. |
| − | for (int i = 0; i < M; i++)
| |
| − | for (int j = 0; j < P; j++) c_back[i][j] = 0.0f;
| |
| | | | |
| − | // Initialize the device queue with the default selector. The device queue is
| + | * VM Service Functions are used for showing when catching errors made in the calculations or accuracy. Such as catching error codes or error messages from improper calculations. |
| − | // used to enqueue kernels. It encapsulates all states needed for execution.
| |
| − | try {
| |
| − | queue q(default_selector{}, dpc_common::exception_handler);
| |
| | | | |
| − | cout << "Device: " << q.get_device().get_info<info::device::name>() << "\n";
| + | === Code Samples === |
| − | | + | These samples are directly from the Intel Math Kernal Library code examples. |
| − | // Create 2D buffers for matrices, buffer c is bound with host memory c_back
| + | All our code examples were taken from the github intel library located at [https://github.com/oneapi-src/oneAPI-samples One API Github] |
| − | | + | ==== Vector Add & MatMul ==== |
| − | buffer<float, 2> a_buf(range(M, N));
| + | The two samples we included in our presentation are specifically located at |
| − | buffer<float, 2> b_buf(range(N, P));
| + | [https://github.com/oneapi-src/oneAPI-samples/blob/master/DirectProgramming/DPC%2B%2B/DenseLinearAlgebra/matrix_mul/src/matrix_mul_omp.cpp Mat Mul] |
| − | buffer c_buf(reinterpret_cast<float *>(c_back), range(M, P));
| + | and |
| − | | + | [https://github.com/oneapi-src/oneAPI-samples/blob/master/DirectProgramming/DPC%2B%2B/DenseLinearAlgebra/vector-add/src/vector-add-usm.cpp Vector-add] |
| − | cout << "Problem size: c(" << M << "," << P << ") = a(" << M << "," << N
| + | located at the links provided. |
| − | << ") * b(" << N << "," << P << ")\n";
| |
| − | | |
| − | // Using three command groups to illustrate execution order. The use of
| |
| − | // first two command groups for initializing matrices is not the most
| |
| − | // efficient way. It just demonstrates the implicit multiple command group
| |
| − | // execution ordering.
| |
| − | | |
| − | // Submit command group to queue to initialize matrix a
| |
| − | q.submit([&](auto &h) {
| |
| − | // Get write only access to the buffer on a device.
| |
| − | accessor a(a_buf, h, write_only);
| |
| − | | |
| − | // Execute kernel.
| |
| − | h.parallel_for(range(M, N), [=](auto index) {
| |
| − | // Each element of matrix a is 1.
| |
| − | a[index] = 1.0f;
| |
| − | });
| |
| − | });
| |
| − | | |
| − | // Submit command group to queue to initialize matrix b
| |
| − | q.submit([&](auto &h) {
| |
| − | // Get write only access to the buffer on a device
| |
| − | accessor b(b_buf, h, write_only);
| |
| − | | |
| − | // Execute kernel.
| |
| − | h.parallel_for(range(N, P), [=](auto index) {
| |
| − | // Each column of b is the sequence 1,2,...,N
| |
| − | b[index] = index[0] + 1.0f;
| |
| − | });
| |
| − | });
| |
| − | | |
| − | // Submit command group to queue to multiply matrices: c = a * b
| |
| − | q.submit([&](auto &h) {
| |
| − | // Read from a and b, write to c
| |
| − | accessor a(a_buf, h, read_only);
| |
| − | accessor b(b_buf, h, read_only);
| |
| − | accessor c(c_buf, h, write_only);
| |
| − | | |
| − | int width_a = a_buf.get_range()[1];
| |
| − | | |
| − | // Execute kernel.
| |
| − | h.parallel_for(range(M, P), [=](auto index) {
| |
| − | // Get global position in Y direction.
| |
| − | int row = index[0];
| |
| − | // Get global position in X direction.
| |
| − | int col = index[1];
| |
| − | | |
| − | float sum = 0.0f;
| |
| − | | |
| − | // Compute the result of one element of c
| |
| − | for (int i = 0; i < width_a; i++) {
| |
| − | sum += a[row][i] * b[i][col];
| |
| − | }
| |
| − | | |
| − | c[index] = sum;
| |
| − | });
| |
| − | });
| |
| − | } catch (sycl::exception const &e) {
| |
| − | cout << "An exception is caught while multiplying matrices.\n";
| |
| − | terminate();
| |
| − | }
| |
| − | | |
| − | int result;
| |
| − | cout << "Result of matrix multiplication using DPC++: ";
| |
| − | result = VerifyResult(c_back);
| |
| − | delete[] c_back;
| |
| − | | |
| − | return result;
| |
| − | }
| |
| − | | |
| − | bool ValueSame(float a, float b) {
| |
| − | return fabs(a - b) < numeric_limits<float>::epsilon();
| |
| − | }
| |
| − | | |
| − | int VerifyResult(float (*c_back)[P]) {
| |
| − | // Check that the results are correct by comparing with host computing.
| |
| − | int i, j, k;
| |
| − | | |
| − | // 2D arrays on host side.
| |
| − | float(*a_host)[N] = new float[M][N];
| |
| − | float(*b_host)[P] = new float[N][P];
| |
| − | float(*c_host)[P] = new float[M][P];
| |
| | | | |
| − | // Each element of matrix a is 1.
| + | === Conclusion === |
| − | for (i = 0; i < M; i++)
| |
| − | for (j = 0; j < N; j++) a_host[i][j] = 1.0f;
| |
| | | | |
| − | // Each column of b_host is the sequence 1,2,...,N
| + | The Intel oneAPI Math Kernel Library is available from the oneAPI base toolkit and it supports programming languages like C, C++, C#, DPC++ and Fortran. These features will help any financial, science or engineering applications run at an optimized level. The MKL is constantly updated on the Intel oneAPI website with lots of examples and tutorials available on their github. If there's any questions, feel free to ask us or refer to the Intel oneAPI website. |
| − | for (i = 0; i < N; i++)
| |
| − | for (j = 0; j < P; j++) b_host[i][j] = i + 1.0f;
| |
| | | | |
| − | // c_host is initialized to zero.
| |
| − | for (i = 0; i < M; i++)
| |
| − | for (j = 0; j < P; j++) c_host[i][j] = 0.0f;
| |
| | | | |
| − | for (i = 0; i < M; i++) {
| |
| − | for (k = 0; k < N; k++) {
| |
| − | // Each element of the product is just the sum 1+2+...+n
| |
| − | for (j = 0; j < P; j++) {
| |
| − | c_host[i][j] += a_host[i][k] * b_host[k][j];
| |
| − | }
| |
| − | }
| |
| − | }
| |
| | | | |
| − | bool mismatch_found = false;
| |
| | | | |
| − | // Compare host side results with the result buffer from device side: print
| + | == Presentation == |
| − | // mismatched data 5 times only.
| |
| − | int print_count = 0;
| |
| | | | |
| − | for (i = 0; i < M; i++) {
| + | Animated GIF of the Presentation |
| − | for (j = 0; j < P; j++) {
| |
| − | if (!ValueSame(c_back[i][j], c_host[i][j])) {
| |
| − | cout << "Fail - The result is incorrect for element: [" << i << ", "
| |
| − | << j << "], expected: " << c_host[i][j]
| |
| − | << ", but found: " << c_back[i][j] << "\n";
| |
| − | mismatch_found = true;
| |
| − | print_count++;
| |
| − | if (print_count == 5) break;
| |
| − | }
| |
| − | }
| |
| | | | |
| − | if (print_count == 5) break;
| + | [[File:Intel Math Kernel Library.gif]] |
| − | }
| |
| | | | |
| − | delete[] a_host;
| + | PDF File: |
| − | delete[] b_host;
| |
| − | delete[] c_host;
| |
| | | | |
| − | if (!mismatch_found) {
| + | [File:https://wiki.cdot.senecacollege.ca/w/imgs/Intel_Math_Kernel_Library.pdf] |
| − | cout << "Success - The results are correct!\n";
| |
| − | return 0;
| |
| − | } else {
| |
| − | cout << "Fail - The results mismatch!\n";
| |
| − | return -1;
| |
| − | }
| |
| − | }
| |
| − | ```
| |
GPU621/DPS921 | Participants | Groups and Projects | Resources | Glossary
Intel Math Kernel Library
Team Name
Slightly Above Average
Group Members
- Jordan Sie
- James Inkster
- Varshan Nagarajan
Progress
100%/100%
Intel Math Library
Introduction
The Intel oneAPI Math Kernel Library (MKL) is the fastest and most widely used math library for all intel based systems. It helps you reach high performance with its enhanced library of optimized math routines. It allows for faster math processing times, increased performance and shorter development times. The MKL supports seven main features; Linear Algebra, Sparse Linear Algebra, Data Fitting, Fast Fourier Transformations, Random Number Generation, Summary Statistics and Vector Math. These features will allow you to optimize applications for all current and future intel CPUs and GPUs.
Features
Linear Algebra
Intel has implemented linear algebra functions that follow industry standards ([BLAS](http://www.netlib.org/blas/) and [LAPACK](http://www.netlib.org/lapack/)). These functions include those that can do the following:
Level 1: Vector-vector operations
Level 2: Matrix-vector operations
Level 3: Matrix-matrix operations
There are many different implementations of these subprograms available. These different implementations are created with different purposes or platforms in mind. Intel's oneAPI implementation heavily focuses on performance, specifically with x86 and x64 in mind.

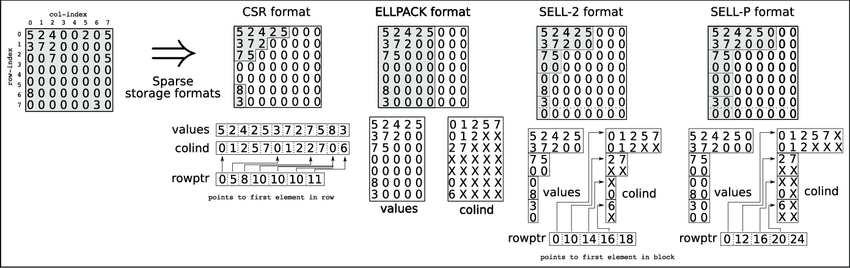
Sparse Linear Algebra Functions
Able to perform low-level inspector-executor routines on sparse matrices, such as:
- Multiply sparse matrix with dense vector
- Multiply sparse matrix with dense matrix
- Solve linear systems with triangular sparse matrices
- Solve linear systems with general sparse matrices
A sparse matrix is matrix that is mostly empty, these are common in machine learning applications. Using standard linear algebra functions would lead to poor performance and would require greater amounts of storage. Specially written sparse linear algebra functions have better performance and can better compress matrices to save space.
Fast Fourier Transforms
Enabling technology today such as most digital communications, audio compression, image compression, satellite tv, FFT is at the heart of it.
A fast Fourier transform (FFT) is an algorithm that computes the discrete Fourier transform (DFT) of a sequence, or its inverse (IDFT).
Random Number Generator
The Intel Math Kernel Library has an interface for RNG routines that use pseudorandom, quasi-random,
and non-deterministic generators. These routines are developed the calls to the highly optimized Basic Random Number Generators (BRNGs).
All BRNGs differentiate in speeds and properties so its easy to find a optimized one for your application.
All RNG routines can be categorized in several different categories.
- Engines - hold the state of a generator
- Transformation classes - holds different types of statistical distribution
- Generate function - the routine that obtains the random number from the statistical distribution
- Services - using routines that can modify the state of the engine
The generation of numbers is done in 2 steps:
1. generate the state using the engine.
2. iterate over the values and the output is the random numbers.
Data Fitting
The Intel Math Kernal Library provide spline-based interpolation that can be ultilized to approximate functions for derivatives, integrals and cell search operations.
Data Fitting routines use the following workflow to process a task:
- Create a task or multiple tasks
- Modify the task parameters
- Perform a Data Fitting computation
- Destroy the task or tasks
Data Fitting functions:
- Task Creation and Initialization Routines
- Task Configuration Routines
Summary Statistics
The Intel Math Kernal Library has an interface for Summary Statistics that can compute estimates for
single, double and multi-dimensional datasets. For example, such parameters may be precision, dimensions of user data, the matrix of the observations, or shapes of data arrays.
First you create and intialize the object for the dataset, then you call the summary statistics routine to calculate the estimate.
Summary Statistics calculate:
- Raw and central sums/moments up to the fourth order.
- Skewness and excess kurtosis.
Additional Features:
- Detect outliers in datasets.
- Support missing values in datasets.
- Parameterize correlation matrices.
- Compute quantiles for streaming data.
Vector Math
There are two main set of functions for the Vector Math library that the intel MKL uses they are:
- VM Mathematical Functions Which allows for it to compute values of mathematical functions e.g. sine, cosine, exponential, or logarithm on vectors that are stored in contiguous memory.
- VM Service Functions are used for showing when catching errors made in the calculations or accuracy. Such as catching error codes or error messages from improper calculations.
Code Samples
These samples are directly from the Intel Math Kernal Library code examples.
All our code examples were taken from the github intel library located at One API Github
Vector Add & MatMul
The two samples we included in our presentation are specifically located at
Mat Mul
and
Vector-add
located at the links provided.
Conclusion
The Intel oneAPI Math Kernel Library is available from the oneAPI base toolkit and it supports programming languages like C, C++, C#, DPC++ and Fortran. These features will help any financial, science or engineering applications run at an optimized level. The MKL is constantly updated on the Intel oneAPI website with lots of examples and tutorials available on their github. If there's any questions, feel free to ask us or refer to the Intel oneAPI website.
Presentation
Animated GIF of the Presentation

PDF File:
[File:https://wiki.cdot.senecacollege.ca/w/imgs/Intel_Math_Kernel_Library.pdf]



