Difference between revisions of "BarraCUDA Boiz"
Mamichalski (talk | contribs) (→Analysis) |
(→Progress) |
||
| (27 intermediate revisions by 3 users not shown) | |||
| Line 411: | Line 411: | ||
==== Problem ==== | ==== Problem ==== | ||
| − | After surveying the original code. We found | + | After surveying the original code. We found three major hot-spots for heavy CPU usage. |
This block of code handles reshapes input pixels into a set of samples for classification. | This block of code handles reshapes input pixels into a set of samples for classification. | ||
| − | + | [[File:SetSamplesSerial.png]] | |
| − | + | ||
| − | + | ||
| − | + | This block of code computes the distances between sampled centers and other input samples. | |
| − | + | ||
| − | + | [[File:CalculateDistanceSerial.png|550px]] | |
| − | + | ||
| − | + | ||
| − | + | This block of code generates the image that has to be outputted. | |
| − | + | ||
| − | + | [[File:GenerateImageSerial.png|550px]] | |
| − | |||
==== Analysis ==== | ==== Analysis ==== | ||
| Line 433: | Line 432: | ||
You can find the new parallelized KmeansPlusPlus code | You can find the new parallelized KmeansPlusPlus code | ||
| − | [https://github.com/ | + | [https://github.com/MajinBui/kmeansplusplusCUDA]. |
| + | |||
| + | |||
| + | Here are the kernels that we programmed. | ||
| + | |||
| + | |||
| + | Set Samples kernel | ||
| + | |||
| + | [[File:SetSamplesKernel.png|550px]] | ||
| + | |||
| + | |||
| + | Calculate Distance kernel | ||
| + | |||
| + | [[File:CalculateDistanceKernel.png|550px]] | ||
| + | |||
| + | Generate Image kernel | ||
| + | |||
| + | [[File:GenerateImageKernel.png|550px]] | ||
| + | |||
| + | |||
| + | |||
| + | ==== Conclusion ==== | ||
| + | |||
| + | By comparing the run-times of the serial KmeansPlusPlus and the parallelized version, we can see that the performance of the program has improved. | ||
| + | |||
| + | [[File:GraphAssignment2.png|900px]] | ||
| + | |||
| + | The performance improvement is not significant for smaller clusters and iterations. But you can see that the performance has been improved for the higher test cases. | ||
| + | |||
| + | === Assignment 3 === | ||
| + | |||
| + | For assignment 3, we optimized the kernels by allocating the correct amounts of grids and block for each kernel. Previously, we allocated 32 threads by 32 blocks for every kernel call even when it did not require it. After adjustments, we found significant improvements for many of the kernels. | ||
| − | + | ====Runtime of program==== | |
| − | + | Here, we see that the program was improved by the optimizations of threads per block. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | Runtime of program: | |
| − | + | For larger images, we found that the program was improved more and more as the amount of clusters and iterations increased. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| + | [[File:Big Image.png]] | ||
| − | + | For medium images, we found more inconsistent results. | |
| − | + | [[File:Med Image.png]] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | For small images, we found the most inconsistent results after optimizations. | |
| − | + | [[File:Small Image.png]] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | When the image side increases, the more efficient the kernel. | |
| − | + | ====Runtime of each kernel==== | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | Each kernel individually found significant or marginal improvements after adjusting for thread/block size. | |
| − | + | Runtime of kernels: | |
| + | |||
| + | Set samples found small improvements on average. | ||
| + | |||
| + | [[File:Set Samples.png]] | ||
| + | |||
| + | Here we changed the calculation of y_index to the outside of the inner loop. | ||
| + | |||
| + | [[File:SetSamplesKernelOptimized.png|550px]] | ||
| + | |||
| + | Calcuate distance found a significant improvements. | ||
| + | |||
| + | [[File:Calculate Distance Kernel.png]] | ||
| + | |||
| + | |||
| + | The biggest change was the thread/block size. | ||
| + | |||
| + | [[File:CalculateDistanceKernelOptimized.png|550px]] | ||
| + | |||
| + | |||
| + | Generate image found improvements as well since image sizes varied. Changing the thread/block size to the correct amount of pixels enabled better usage of memory. | ||
| + | |||
| + | [[File:Generate Image Kernel.png]] | ||
| − | + | The biggest change was the thread/block size. | |
| − | + | [[File:GenerateImageKernelOptimized.png|550px]] | |
Latest revision as of 23:53, 13 April 2017
Contents
BarraCUDA Boiz
Team Members
Progress
Assignment 1
✗ EucideanDistance
Profiled the following project on github which finds the euclidean distance transformation on given chart formatted in a text file. The project can be found here: here
The following is a example of the program running with an example input and the output afterwards.
Before: After: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 0 0 1 1 2 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 1 2 3 2 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 1 1 2 3 4 3 2 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 1 2 3 4 4 4 3 2 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 0 1 1 2 3 4 4 5 4 4 3 2 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 1 2 3 4 4 5 6 5 4 4 3 2 1 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 1 0 1 2 3 4 5 6 7 6 5 4 3 2 1 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 1 0 1 2 3 4 5 6 7 6 5 4 3 2 1 0 0 0 0 0 0 1 0 0 0 0 1 1 1 0 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 1 1 1 0 1 0 0 1 2 3 4 5 5 6 5 5 4 3 2 1 1 1 1 1 1 1 0 0 0 0 0 1 0 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1 2 3 3 4 4 5 4 4 3 3 2 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 0 1 1 2 2 3 4 4 4 3 2 2 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 1 2 3 4 3 2 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 1 1 1 1 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 2 3 2 1 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 1 1 2 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 2 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 1 2 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 2 3 2 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 1 1 1 1 1 1 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 1 2 3 4 3 2 1 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 1 1 2 3 4 4 4 3 2 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 2 3 4 4 5 4 4 3 2 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 4 4 5 6 5 4 4 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 4 5 6 7 6 5 4 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 2 3 4 5 6 7 6 5 4 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 2 3 4 5 5 6 5 5 4 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 2 3 3 4 4 5 4 4 3 3 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 2 2 3 4 4 4 3 2 2 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 1 1 1 2 3 4 3 2 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 1 1 2 3 2 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 0 0 0 1 1 2 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 0 0 1 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
At n = 1302:
Flat profile: Each sample counts as 0.01 seconds. no time accumulated % cumulative self self total time seconds seconds calls Ts/call Ts/call name 0.00 0.00 0.00 810 0.00 0.00 EuclideanDistanceTransform::loadNeighbors(int, int, int) 0.00 0.00 0.00 1 0.00 0.00 _GLOBAL__sub_I__ZN26EuclideanDistanceTransformC2ERSt14basic_ifstreamIcSt11char_traitsIcEERSt14basic_ofstreamIcS2_ES7_ 0.00 0.00 0.00 1 0.00 0.00 EuclideanDistanceTransform::zeroFramed() 0.00 0.00 0.00 1 0.00 0.00 EuclideanDistanceTransform::firstPassEuclideanDistance(std::basic_ofstream<char, std::char_traits<char> >&) 0.00 0.00 0.00 1 0.00 0.00 EuclideanDistanceTransform::secondPassEuclideanDistance(std::basic_ofstream<char, std::char_traits<char> >&) 0.00 0.00 0.00 1 0.00 0.00 EuclideanDistanceTransform::loadImage(std::basic_ifstream<char, std::char_traits<char> >&)
At n = 1000000:
Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 33.33 0.03 0.03 1 30.00 30.00 EuclideanDistanceTransform::loadImage(std::basic_ifstream<char, std::char_traits<char> >&) 22.22 0.05 0.02 1001696 0.00 0.00 EuclideanDistanceTransform::loadNeighbors(int, int, int) 22.22 0.07 0.02 EuclideanDistanceTransform::EuclideanDistanceTransform(std::basic_ifstream<char, std::char_traits<char> >&, std::basic_ofstream<char, std::char_traits<char> >&, std::basic_ofstream<char, std::char_traits<char> >&) 11.11 0.08 0.01 1 10.00 20.00 EuclideanDistanceTransform::firstPassEuclideanDistance(std::basic_ofstream<char, std::char_traits<char> >&) 11.11 0.09 0.01 1 10.00 20.00 EuclideanDistanceTransform::secondPassEuclideanDistance(std::basic_ofstream<char, std::char_traits<char> >&) 0.00 0.09 0.00 1 0.00 0.00 _GLOBAL__sub_I__ZN26EuclideanDistanceTransformC2ERSt14basic_ifstreamIcSt11char_traitsIcEERSt14basic_ofstreamIcS2_ES7_ 0.00 0.09 0.00 1 0.00 0.00 EuclideanDistanceTransform::zeroFramed()
At n = 10000000:
Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 35.14 0.26 0.26 EuclideanDistanceTransform::EuclideanDistanceTransform(std::basic_ifstream<char, std::char_traits<char> >&, std::basic_ofstream<char, std::char_traits<char> >&, std::basic_ofstream<char, std::char_traits<char> >&) 27.03 0.46 0.20 1 200.00 255.00 EuclideanDistanceTransform::secondPassEuclideanDistance(std::basic_ofstream<char, std::char_traits<char> >&) 20.27 0.61 0.15 1 150.00 205.00 EuclideanDistanceTransform::firstPassEuclideanDistance(std::basic_ofstream<char, std::char_traits<char> >&) 14.86 0.72 0.11 9998998 0.00 0.00 EuclideanDistanceTransform::loadNeighbors(int, int, int) 2.70 0.74 0.02 1 20.00 20.00 EuclideanDistanceTransform::loadImage(std::basic_ifstream<char, std::char_traits<char> >&) 0.00 0.74 0.00 1 0.00 0.00 _GLOBAL__sub_I__ZN26EuclideanDistanceTransformC2ERSt14basic_ifstreamIcSt11char_traitsIcEERSt14basic_ofstreamIcS2_ES7_ 0.00 0.74 0.00 1 0.00 0.00 EuclideanDistanceTransform::zeroFramed()
✗ SeamCarving
Seam carving (or liquid re-scaling) is an algorithm for content-aware image resizing. It functions by establishing a number of seams (paths of least importance) in an image and automatically removes seams to reduce image size or inserts seams to extend it. The profiled project can be found on Github using this link: here
Opencv setup instructions (linux):
Required : opencv, cmake, g++, make, gprof
1) sudo apt-get install build-essential cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
2) Downoad opencv version 2.4.13 here and extract it
3) cd opencv-2.4.13
4) mkdir build
5) cd build
6) cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
7) make -j7
8) sudo make install
At this point we recomend you test to see if opencv is working correctly by following this
Build SeamCarving:
1) create "CMakeLists.txt"
cmake_minimum_required(VERSION 2.8)
project( SeamCarving )
find_package( OpenCV REQUIRED )
add_executable( SeamCarving main.cpp )
target_link_libraries( SeamCarving ${OpenCV_LIBS} )
2) cmake -DCMAKE_CXX_FLAGS=-pg -DCMAKE_EXE_LINKER_FLAGS=-pg -DCMAKE_SHARED_LINKER_FLAGS=-pg .
3) make
Note possible errors (if compiling from original source):
1) Error : "opencv2\opencv.hpp: No such file or directory #include <opencv2\opencv.hpp>"
Solution : Change '<opencv2\opencv.hpp>' to '<opencv2/opencv.hpp>'
2) Error : " 'printf' was not declared in this scope"
Solution : add "#include <stdio.h>"
4) ./SeamCarving <source_img>
5) gprof -p -b ./SeamCarving > SeamCarving.flt
Here is an example of a test case:
I shrunk the image by 1000 pixels. Before:After:



On shrinking by 100 pixels.
Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 36.84 5.87 5.87 2549733700 0.00 0.00 unsigned char& cv::Mat::at<unsigned char>(int, int) 24.50 9.77 3.90 100 39.02 71.54 computeSeam(cv::_InputArray const&, std::vector<int, std::allocator<int> >&) 11.31 11.57 1.80 100 18.01 46.39 void carveSeam<unsigned char>(cv::Mat&, std::vector<int, std::allocator<int> >&) 7.76 12.81 1.24 558300205 0.00 0.00 int& cv::Mat::at<int>(int, int) 6.28 13.81 1.00 100 10.01 37.36 detectEdge(cv::_InputArray const&, cv::_OutputArray const&) 3.58 14.38 0.57 186060000 0.00 0.00 cvRound(double) 2.89 14.84 0.46 186060000 0.00 0.00 unsigned char cv::saturate_cast<unsigned char>(double) 2.64 15.26 0.42 186060000 0.00 0.00 unsigned char cv::saturate_cast<unsigned char>(int) 2.14 15.60 0.34 cv::Size_<int>::Size_(int, int) 1.70 15.87 0.27 186060000 0.00 0.00 std::vector<int, std::allocator<int> >::operator[](unsigned long) 0.44 15.94 0.07 frame_dummy 0.00 15.94 0.00 1003 0.00 0.00 cv::Mat::release()
On shrinking by 500 pixels.
Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 37.44 30.05 30.05 11103057554 0.00 0.00 unsigned char& cv::Mat::at<unsigned char>(int, int) 24.22 49.49 19.44 500 38.88 71.23 computeSeam(cv::_InputArray const&, std::vector<int, std::allocator<int> >&) 12.09 59.19 9.71 500 19.41 48.18 void carveSeam<unsigned char>(cv::Mat&, std::vector<int, std::allocator<int> >&) 7.57 65.27 6.07 500 12.15 37.01 detectEdge(cv::_InputArray const&, cv::_OutputArray const&) 7.17 71.02 5.75 2431501402 0.00 0.00 int& cv::Mat::at<int>(int, int) 2.94 73.38 2.36 810300000 0.00 0.00 cvRound(double) 2.46 75.36 1.98 810300000 0.00 0.00 unsigned char cv::saturate_cast<unsigned char>(double) 2.23 77.15 1.79 cv::Size_<int>::Size_(int, int) 1.89 78.66 1.52 810300000 0.00 0.00 unsigned char cv::saturate_cast<unsigned char>(int) 1.55 79.90 1.24 810300000 0.00 0.00 std::vector<int, std::allocator<int> >::operator[](unsigned long) 0.36 80.19 0.29 frame_dummy 0.12 80.29 0.10 500 0.20 0.20 std::vector<int, std::allocator<int> >::resize(unsigned long, int) 0.00 80.29 0.00 5003 0.00 0.00 cv::Mat::release()
On shrinking by 1000 pixels.
Flat profile: Each sample counts as 0.01 seconds. % cumulative self self total time seconds seconds calls ms/call ms/call name 38.13 40.06 40.06 18093467576 0.00 0.00 unsigned char& cv::Mat::at<unsigned char>(int, int) 24.02 65.30 25.23 1000 25.23 47.05 computeSeam(cv::_InputArray const&, std::vector<int, std::allocator<int> >&) 11.98 77.88 12.59 1000 12.59 32.07 void carveSeam<unsigned char>(cv::Mat&, std::vector<int, std::allocator<int> >&) 7.63 85.90 8.01 3963002390 0.00 0.00 int& cv::Mat::at<int>(int, int) 6.77 93.01 7.11 1000 7.11 23.07 detectEdge(cv::_InputArray const&, cv::_OutputArray const&) 2.56 95.70 2.69 1320600000 0.00 0.00 cvRound(double) 2.55 98.38 2.68 cv::Size_<int>::Size_(int, int) 2.25 100.75 2.37 1320600000 0.00 0.00 unsigned char cv::saturate_cast<unsigned char>(double) 2.02 102.88 2.13 1320600000 0.00 0.00 unsigned char cv::saturate_cast<unsigned char>(int) 1.87 104.84 1.96 1320600000 0.00 0.00 std::vector<int, std::allocator<int> >::operator[](unsigned long) 0.23 105.08 0.24 frame_dummy 0.04 105.12 0.04 1000 0.04 0.04 std::vector<int, std::allocator<int> >::resize(unsigned long, int)
✓ KmeansPlusPlus
Kmeansplusplus is a clustering method that determins which in this case takes an image and splits it into k number of clusters. For an image it selects k number of pixels and uses those pixels as a reference point to compare all the other pixels to change their colors based on which reference pixel they are closest to. The first integer is k (the number of reference points), the second integer is the number of times to iterate through the image.
Original source code can be found here
Opencv setup instructions (linux):
Required : opencv, cmake, g++, make, gprof
1) sudo apt-get install build-essential cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
2) Downoad opencv version 2.4.13 here and extract it
3) cd opencv-2.4.13
4) mkdir build
5) cd build
6) cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
7) make -j7
8) sudo make install
At this point we recomend you test to see if opencv is working correctly by following this
Build KmeansPlusPlus :
1) create "CMakeLists.txt"
cmake_minimum_required(VERSION 2.8)
project( Kmeans++ )
find_package( OpenCV REQUIRED )
add_executable( Kmeans++ main.cpp mt19937ar.c )
target_link_libraries( Kmeans++ ${OpenCV_LIBS} )
2) cmake -DCMAKE_CXX_FLAGS=-pg -DCMAKE_EXE_LINKER_FLAGS=-pg -DCMAKE_SHARED_LINKER_FLAGS=-pg .
3) make
Note possible errors (if compiling from original source):
1) Error : "opencv2\opencv.hpp: No such file or directory #include <opencv2\opencv.hpp>"
Solution : Change '<opencv2\opencv.hpp>' to '<opencv2/opencv.hpp>'
2) Error : " 'printf' was not declared in this scope"
Solution : add "#include <stdio.h>"
4) ./Kmeans++ <source_img> <output_img> <#clusters> <#iterations>
5) gprof -p -b ./Kmeans++ > Kmeans++.flt
Original Image :

Test Cases:
Command line: ./Kmeans++ baboon.jpg baboon_out_5x100.jpg 5 100
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total time seconds seconds calls s/call s/call name 50.51 1.60 1.60 951584265 0.00 0.00 float& cv::Mat::at<float>(int, int) 42.62 2.95 1.35 1 1.35 3.15 kmeanspp(cv::Mat&, cv::Mat&, cv::Mat&, cv::Mat&, int, int) 4.26 3.09 0.14 78906844 0.00 0.00 int& cv::Mat::at<int>(int, int) 1.89 3.15 0.06 1 0.06 0.06 std::vector<double, std::allocator<double> >::~vector() 0.32 3.16 0.01 1572864 0.00 0.00 unsigned char& cv::Mat::at<unsigned char>(int, int) 0.32 3.17 0.01 main 0.16 3.17 0.01 3053814 0.00 0.00 std::vector<double, std::allocator<double> >::operator[](unsigned long)

Command line: ./Kmeans++ baboon.jpg baboon_out_5x500.jpg 5 500
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total time seconds seconds calls s/call s/call name 45.62 7.34 7.34 1 7.34 16.11 kmeanspp(cv::Mat&, cv::Mat&, cv::Mat&, cv::Mat&, int, int) 43.88 14.41 7.06 4726463865 0.00 0.00 float& cv::Mat::at<float>(int, int) 6.90 15.52 1.11 393485644 0.00 0.00 int& cv::Mat::at<int>(int, int) 3.17 16.03 0.51 1 0.51 0.51 std::vector<double, std::allocator<double> >::~vector() 0.44 16.10 0.07 3273980 0.00 0.00 std::vector<double, std::allocator<double> >::operator[](unsigned long) 0.06 16.11 0.01 1 0.01 0.01 std::vector<double, std::allocator<double> >::vector(unsigned long, double const&, std::allocator<double> const&)
Command line: ./Kmeans++ baboon.jpg baboon_out_100x5.jpg 100 5
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total time seconds seconds calls s/call s/call name 46.29 1.30 1.30 1 1.30 2.79 kmeanspp(cv::Mat&, cv::Mat&, cv::Mat&, cv::Mat&, int, int) 45.94 2.59 1.29 951585120 0.00 0.00 float& cv::Mat::at<float>(int, int) 4.27 2.71 0.12 66348332 0.00 0.00 std::vector<double, std::allocator<double> >::operator[](unsigned long) 2.49 2.78 0.07 1 0.07 0.07 std::vector<double, std::allocator<double> >::~vector() 0.71 2.80 0.02 main 0.36 2.81 0.01 1 0.01 0.01 std::vector<double, std::allocator<double> >::vector(unsigned long, double const&, std::allocator<double> const&)
Command line: ./Kmeans++ baboon.jpg baboon_out_500x5.jpg 500 5
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total time seconds seconds calls s/call s/call name 49.65 7.07 7.07 4726468320 0.00 0.00 float& cv::Mat::at<float>(int, int) 44.97 13.47 6.40 1 6.40 14.22 kmeanspp(cv::Mat&, cv::Mat&, cv::Mat&, cv::Mat&, int, int) 2.53 13.83 0.36 327813766 0.00 0.00 std::vector<double, std::allocator<double> >::operator[](unsigned long) 2.28 14.16 0.33 1 0.33 0.33 std::vector<double, std::allocator<double> >::~vector() 0.42 14.22 0.06 1 0.06 0.06 std::vector<double, std::allocator<double> >::vector(unsigned long, double const&, std::allocator<double> const&) 0.14 14.24 0.02 main 0.07 14.25 0.01 1572864 0.00 0.00 unsigned char& cv::Mat::at<unsigned char>(int, int)
Command line: ./Kmeans++ baboon.jpg baboon_out_100x100.jpg 100 100
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total time seconds seconds calls s/call s/call name 69.03 60.68 60.68 1 60.68 87.95 kmeanspp(cv::Mat&, cv::Mat&, cv::Mat&, cv::Mat&, int, int) 28.80 86.00 25.32 7453309108 0.00 0.00 float& cv::Mat::at<float>(int, int) 1.95 87.71 1.71 1 1.71 1.71 std::vector<double, std::allocator<double> >::~vector() 0.15 87.84 0.14 78935344 0.00 0.00 int& cv::Mat::at<int>(int, int) 0.11 87.94 0.10 66396782 0.00 0.00 std::vector<double, std::allocator<double> >::operator[](unsigned long) 0.02 87.96 0.02 1 0.02 0.02 std::vector<double, std::allocator<double> >::vector(unsigned long, double const&, std::allocator<double> const&)
Command line: ./Kmeans++ baboon.jpg baboon_out_500x500.jpg 500 500
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total time seconds seconds calls Ks/call Ks/call name 54.00 919.48 919.48 1 0.92 1.70 kmeanspp(cv::Mat&, cv::Mat&, cv::Mat&, cv::Mat&, int, int) 44.16 1671.44 751.95 8242561860 0.00 0.00 float& cv::Mat::at<float>(int, int) 1.82 1702.36 30.93 1 0.03 0.03 std::vector<double, std::allocator<double> >::~vector() 0.06 1703.31 0.95 394228144 0.00 0.00 int& cv::Mat::at<int>(int, int) 0.03 1703.75 0.44 329563076 0.00 0.00 std::vector<double, std::allocator<double> >::operator[](unsigned long) 0.00 1703.78 0.03 1 0.00 0.00 std::vector<double, std::allocator<double> >::vector(unsigned long, double const&, std::allocator<double> const&) 0.00 1703.79 0.01 1572864 0.00 0.00 unsigned char& cv::Mat::at<unsigned char>(int, int) 0.00 1703.80 0.01 1 0.00 0.00 __gnu_cxx::__enable_if<std::__is_scalar<double>::__value, double*>::__type std::__fill_n_a<double*, unsigned long, double>(double*, unsigned long, double const&)

As you can see if you select a lot of clusters the image will appear very similar to the original but if you select a small number of clusters most of the detail is gone.
Conclusion and Observations
While the EucideanDistance project shows great promise in being optimized and parallelized (will be upwards of 90% once redundant functions are merged), it suffers from the draw back of having limited test data. The test data required for the EucideanDistance project is a text based image based in 1s and 0s. Along with this, the 'image' file used is also rather unpresentable.
The seam carver project displays poor results in regards of parallelization and optimization. There is no real identifiable hotspot in any of the function calls.
The KmeansPlusPlus project shows to be somewhat promising in regards to parallelization and optimization. At first glance, there does not seem to be a exact hotspot as two functions take around 50% of the work. However, on close examination, one of the function take 50% but is only called once in one project execution vs the other at above 8 million. Optimizing and improving at least the one portion of this project would prove to be advantageous.
In conclusion, our findings indicate that KmeansPlusPlus would be the best project to continue onto assignment 2, with EucideanDistance as the back up.
Assignment 2
Problem
After surveying the original code. We found three major hot-spots for heavy CPU usage.
This block of code handles reshapes input pixels into a set of samples for classification.
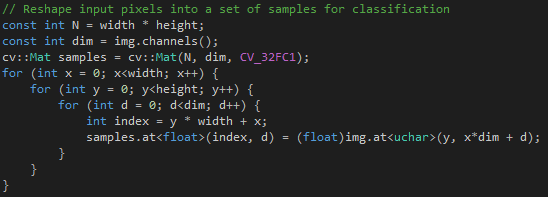

This block of code computes the distances between sampled centers and other input samples.
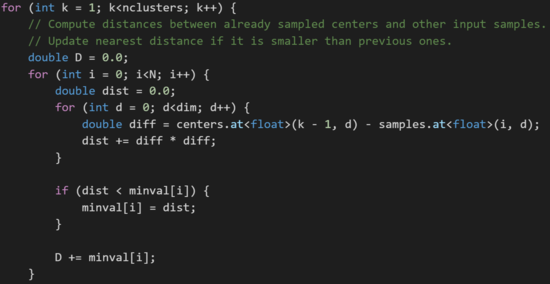

This block of code generates the image that has to be outputted.
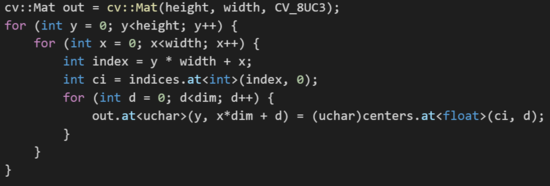

Analysis
After analyzing this block of code. We decided to parallelize it.
You can find the new parallelized KmeansPlusPlus code [1].
Here are the kernels that we programmed.
Set Samples kernel
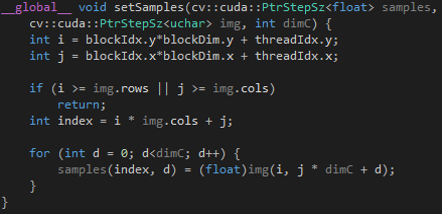

Calculate Distance kernel
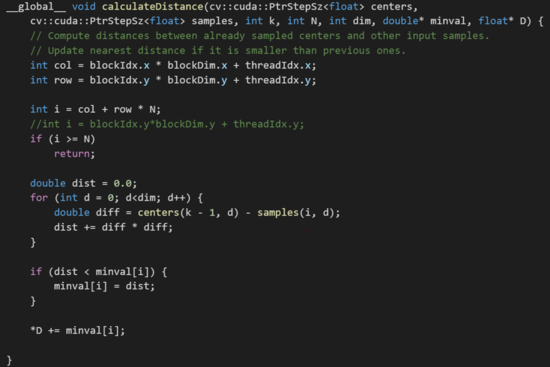

Generate Image kernel
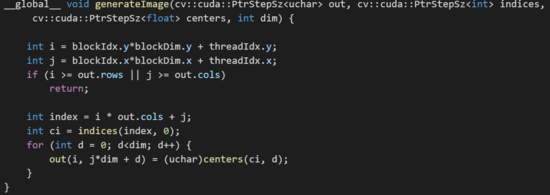

Conclusion
By comparing the run-times of the serial KmeansPlusPlus and the parallelized version, we can see that the performance of the program has improved.

The performance improvement is not significant for smaller clusters and iterations. But you can see that the performance has been improved for the higher test cases.
Assignment 3
For assignment 3, we optimized the kernels by allocating the correct amounts of grids and block for each kernel. Previously, we allocated 32 threads by 32 blocks for every kernel call even when it did not require it. After adjustments, we found significant improvements for many of the kernels.
Runtime of program
Here, we see that the program was improved by the optimizations of threads per block.
Runtime of program:
For larger images, we found that the program was improved more and more as the amount of clusters and iterations increased.

For medium images, we found more inconsistent results.

For small images, we found the most inconsistent results after optimizations.

When the image side increases, the more efficient the kernel.
Runtime of each kernel
Each kernel individually found significant or marginal improvements after adjusting for thread/block size.
Runtime of kernels:
Set samples found small improvements on average.

Here we changed the calculation of y_index to the outside of the inner loop.

Calcuate distance found a significant improvements.

The biggest change was the thread/block size.

Generate image found improvements as well since image sizes varied. Changing the thread/block size to the correct amount of pixels enabled better usage of memory.

The biggest change was the thread/block size.
